This chapter will be a brief introduction to the analysis of algorithms. As we have already seen in the past couple of chapters, timing algorithms is a decent way to determining how well they run, however sometimes a more in-depth analysis is needed. We will cover what is called big-O notation and analyze a few algorithms here.
If we evaluate the polynomial as is counting powers as repeated multiplication, then the number of additions is \(n\) and the number of multiplication is
In this case, there are \(n\) additions and \(n\) multiplications. So you could say that the total number of operations are \(c_1 n + c_2n\) where \(c_1\) and \(c_2\) are constants related to addition and multiplication. Overall, this means that the order of polynomial evaluation using Horner’s method is \(O(n)\text{.}\)
function poly1(coeffs::Vector{T}, x::S) where {T <: Number, S <: Number}
local sum = zero(T)
function pow(x::T,n::Int) where T <: Number
local prod = one(T)
for j=1:n
prod *=x
end
prod
end
for n=1:length(coeffs)
sum += coeffs[n]*pow(x,n-1)
end
sum
end
where the where {T <: Number, S <: Number} will be explained in Chapter 11, but this allows any subtype of Number to be taken. Also, we have defined the power to be repeated multiplication using a for loop, since Julia’s power function is quite efficient--we want to show the results from above.
Let’s do some testing and we’ll need the BenchmarkTools and CairoMakie (for plotting). We also need Random to set the seed and LsqFit to fit the data we’ll generate to a curve.
using BenchmarkTools, CairoMakie, Random, LsqFit
CairoMakie.activate!()
Random.seed!(132)
There are a few plots in this section and we will be using a package called Makie to do the plots. We will explore this in detail in Chapter 14, however, copying the code to produce the plots is sufficient for this chapter.
The following will time using the @belapsed macro which returns the amount of time a function takes given in seconds. This is needed because we need to store the result. Note that in the previous chapters we’ve used the @btime macro which times the function and gives additional information as well as the return value. We are only interested in the amount of time in this section.
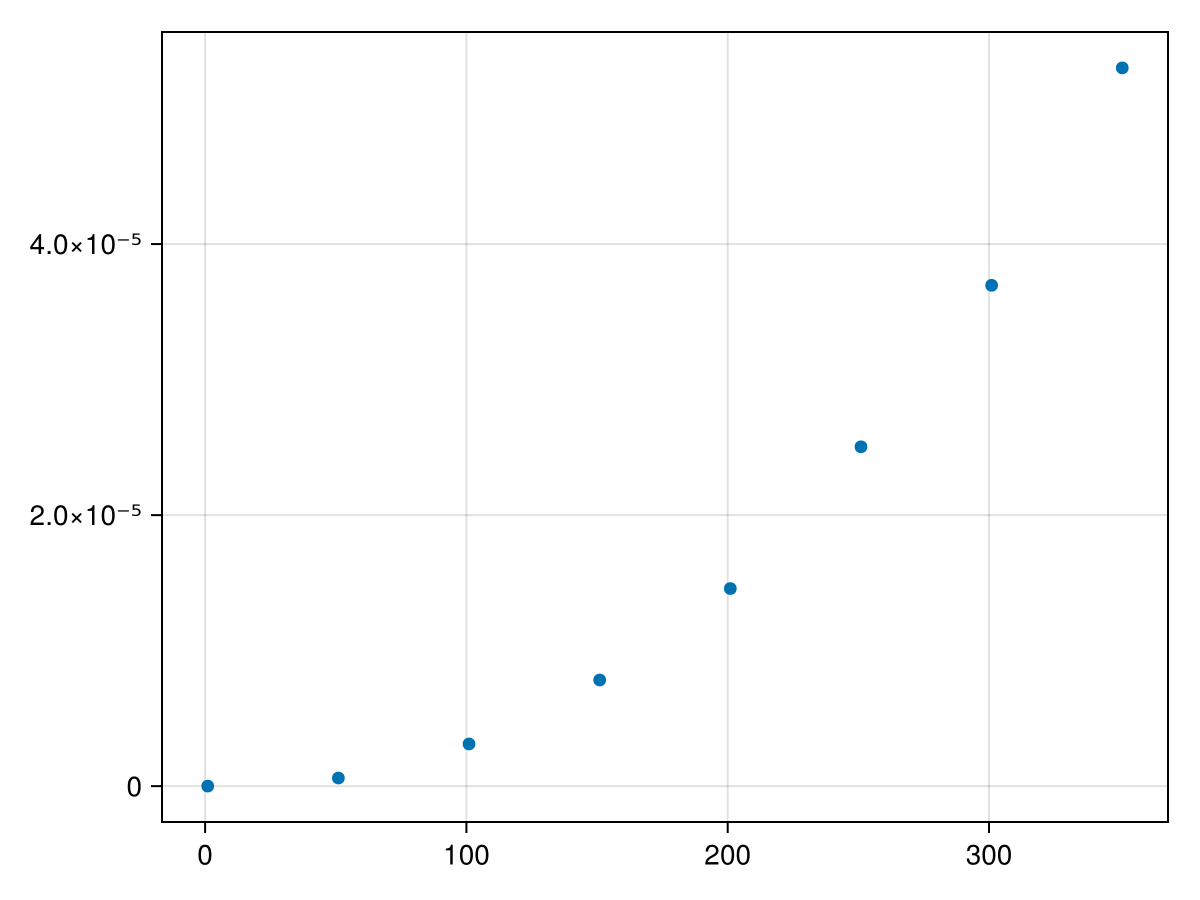
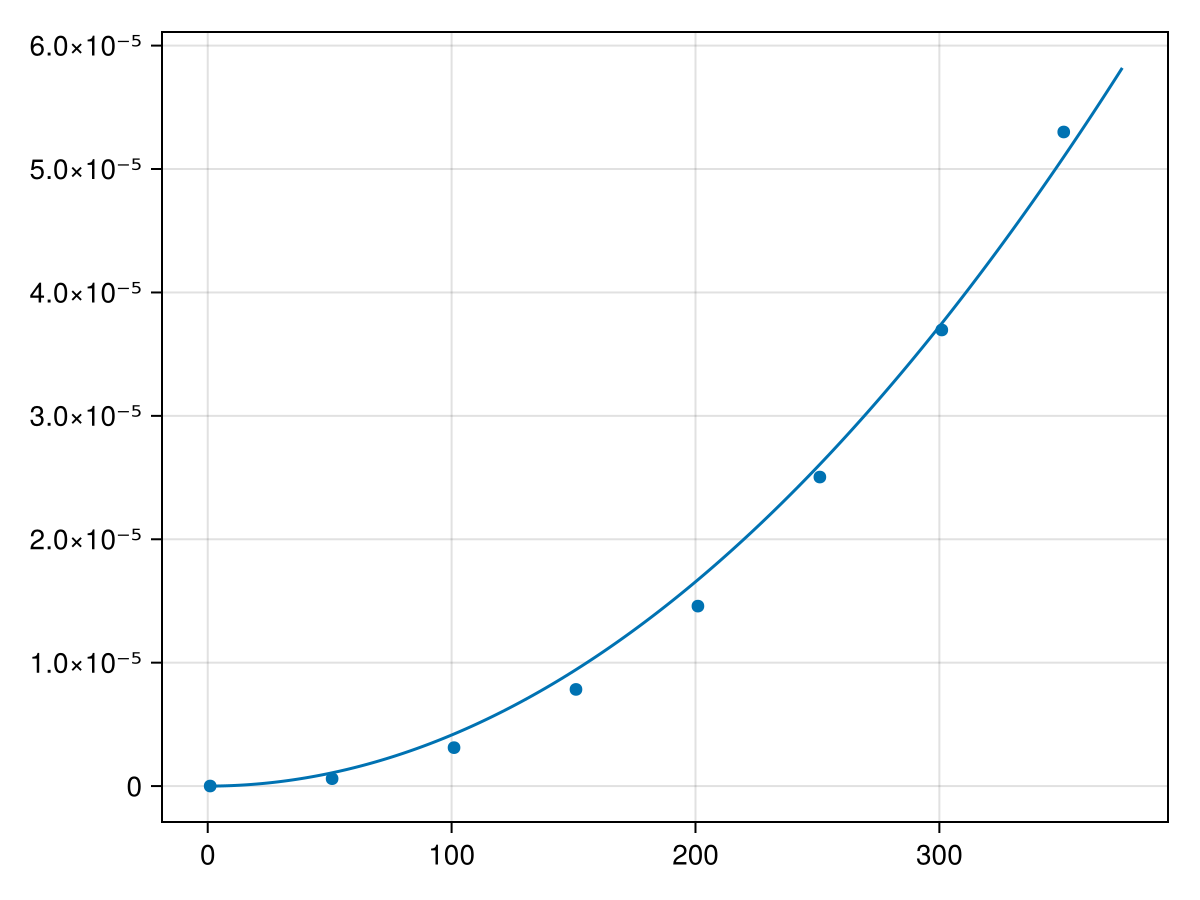
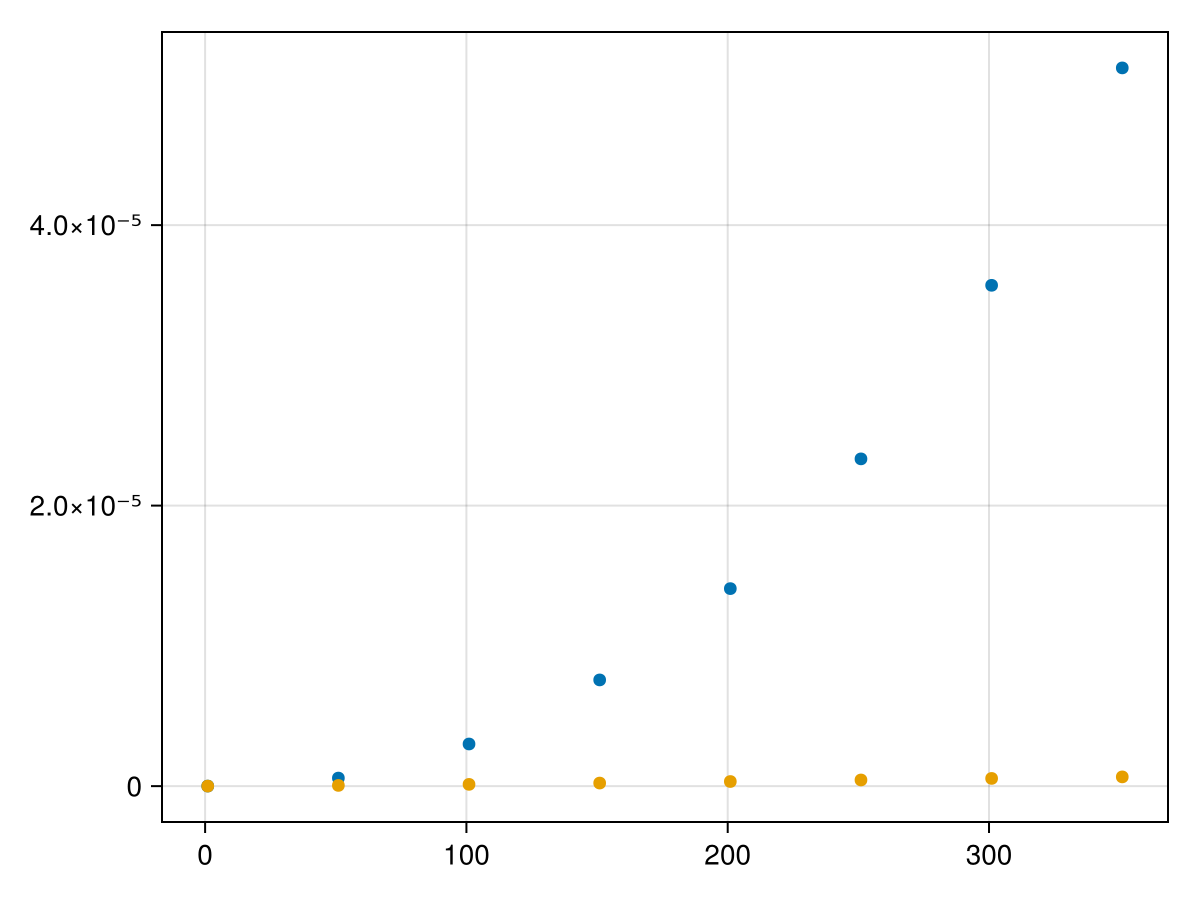
Hopefully visually you can see that it appears to be nonlinear and perhaps you can see that it is may be quadratic. We will fit a quadratic to these points by first defining the model as a quadratic:
and note that the output will not be particularly helpful. What we are looking for are the best-fit parameters and these can be found with fit.param and the results are
These are all small, however, the important thing to determine is if they are possibly zero. We can use the confidence interval of each is found with confidence_interval(fit, 0.05) which returns
These show the 95%-confidence intervals for the three parameters. We are looking for the largest non-zero term, which is the third one. Since the above fits all three terms, we will redo the fit with only the third term as
function horner(coeffs::Vector{T},x::S) where {T <: Number, S <: Number}
local result = coeffs[end]
for i=length(coeffs)-1:-1:1
result = x*result+coeffs[i]
end
result
end
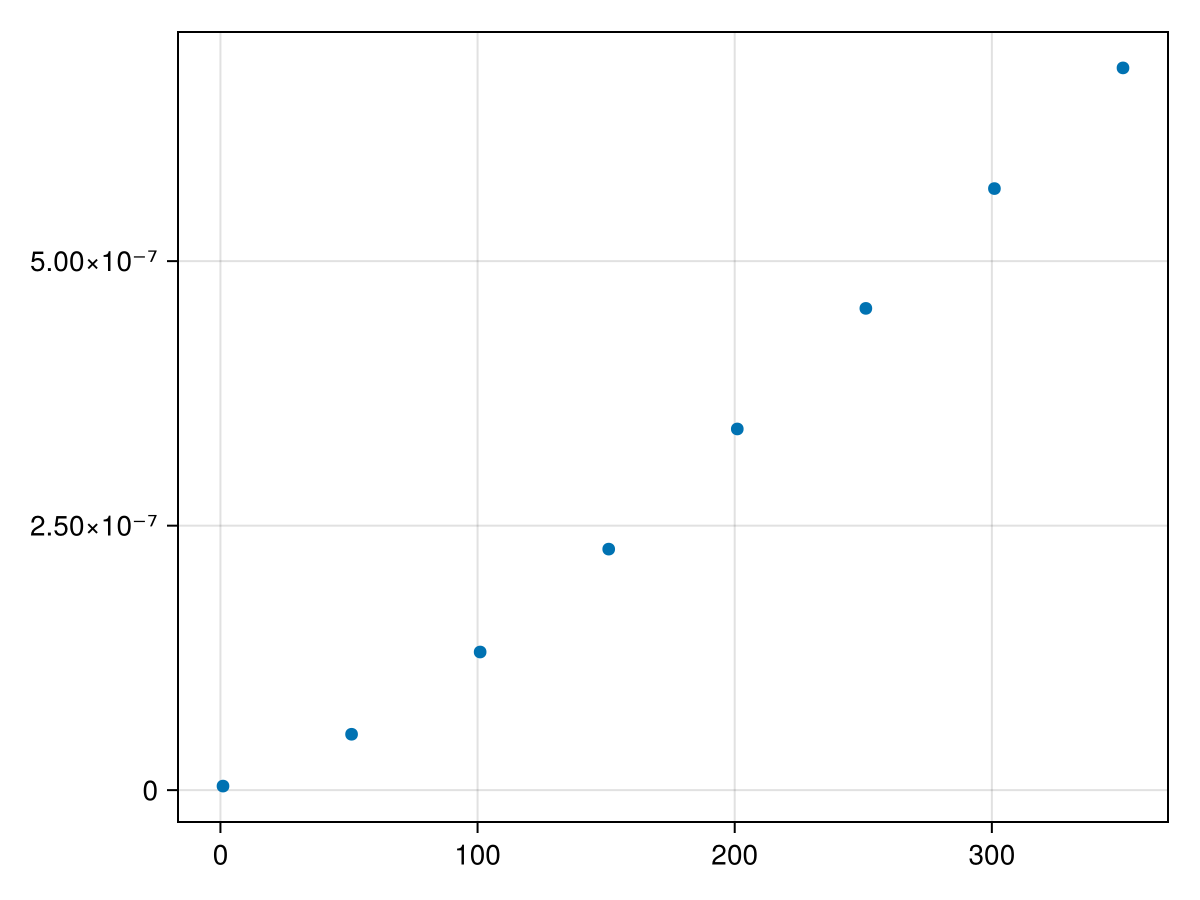
and then similar to above, we will time this method for different lengths:
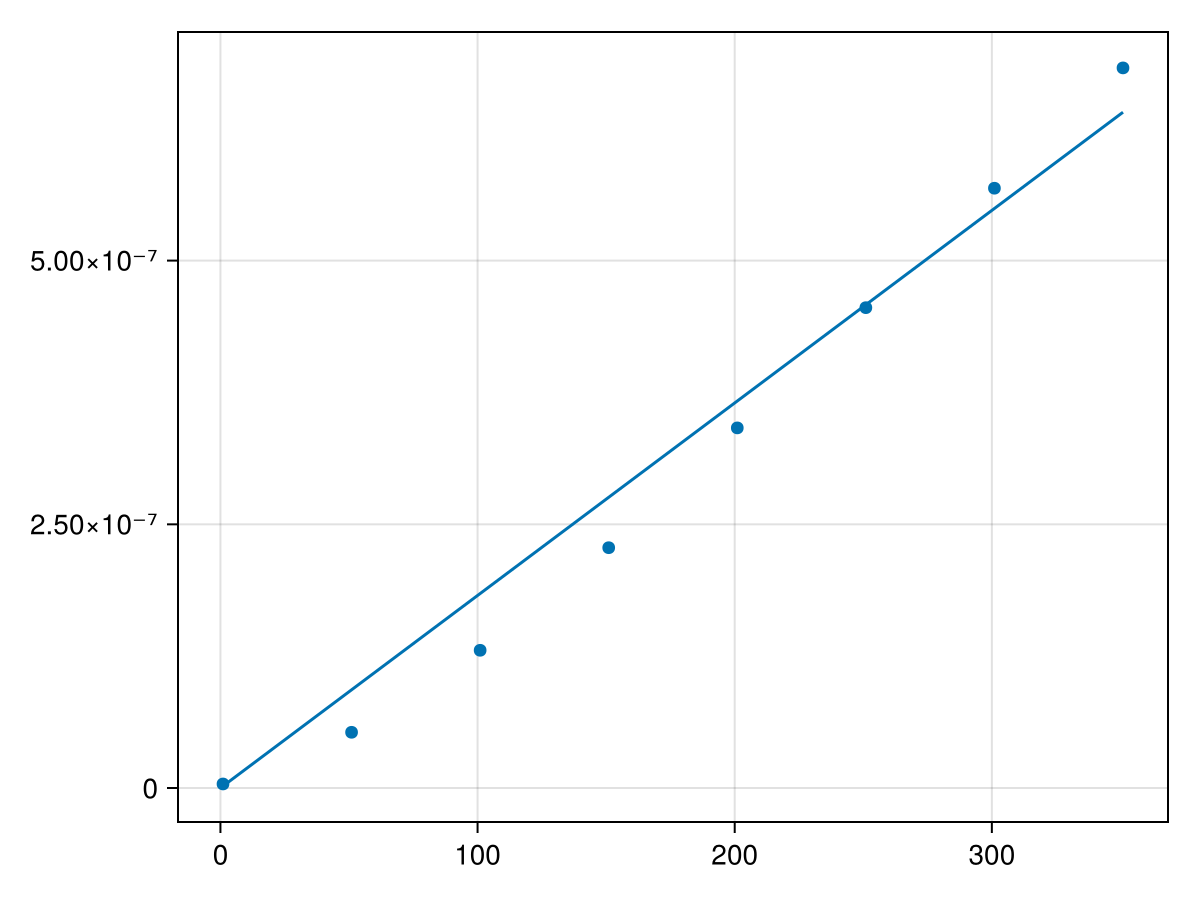
and if you’re interested in the value of the parameter (slope of the line), fit3.param returns 1.8253874361922209e-9. Looking at it visually, let’s add the plot of the line to the scatter plot above with
Overall, these results show that the time taken to evaluate a polynomial using Horner’s form, is \(O(n)\text{.}\) This evidence shows that Horner’s form of the polynomial is much faster and putting these two scatter plots together with:
Typically algorithms grows as some function of \(n\text{,}\) which is a measure of the size of the problem. Determining the order of the algorithm can be tricky although we can use numerics like above to find the timing of algorithms for various sizes of the problem. Then doing some data-fitting, we can often find the order of the algorithm. We’ll see another example of this in the next section.
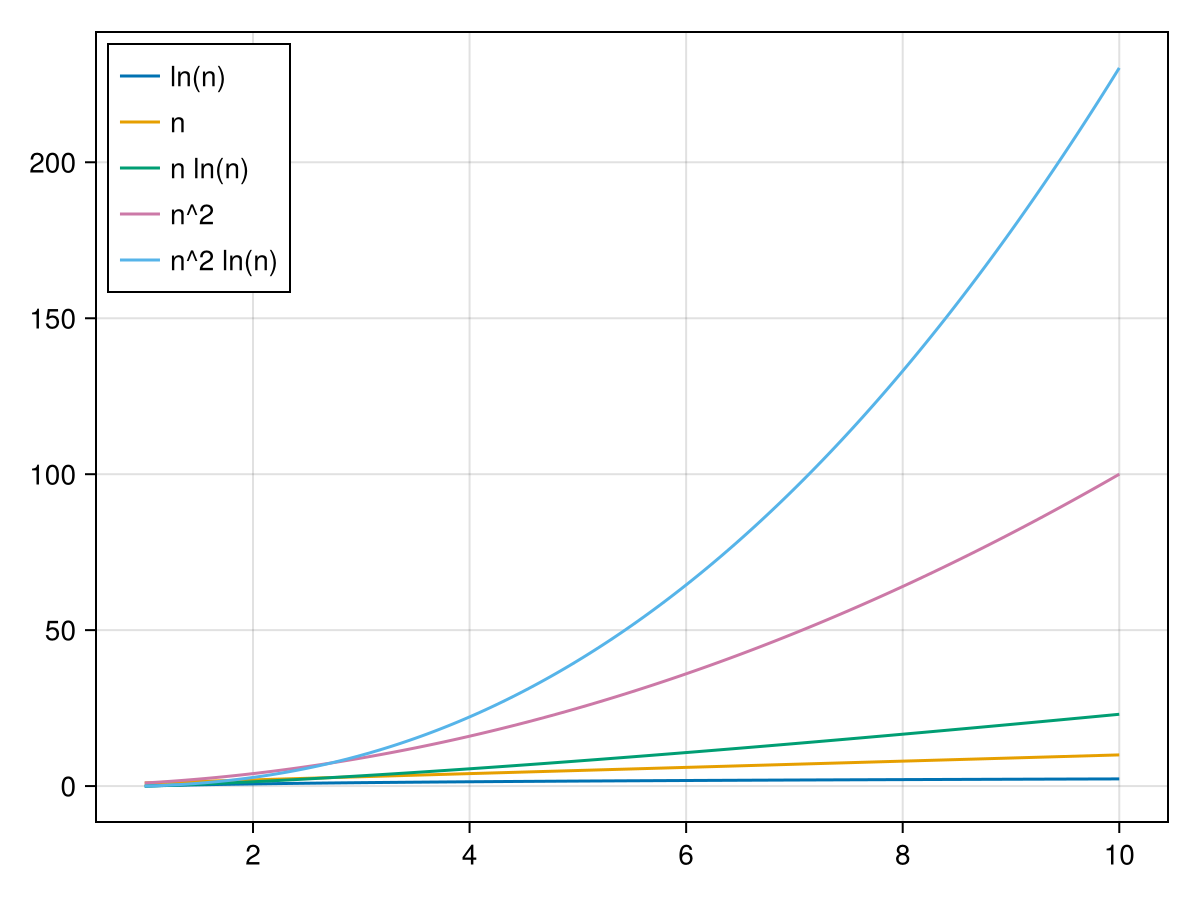
Understanding different orders is helpful and this means understanding how functions grow. Here are a bunch of standard algorithm functions and their plots:
This would basically show that if there are choices of algorithms, to use an algorithm with a lower order in that for large values of problem size will run faster.
Section28.4Using Data to determine Algorithm order
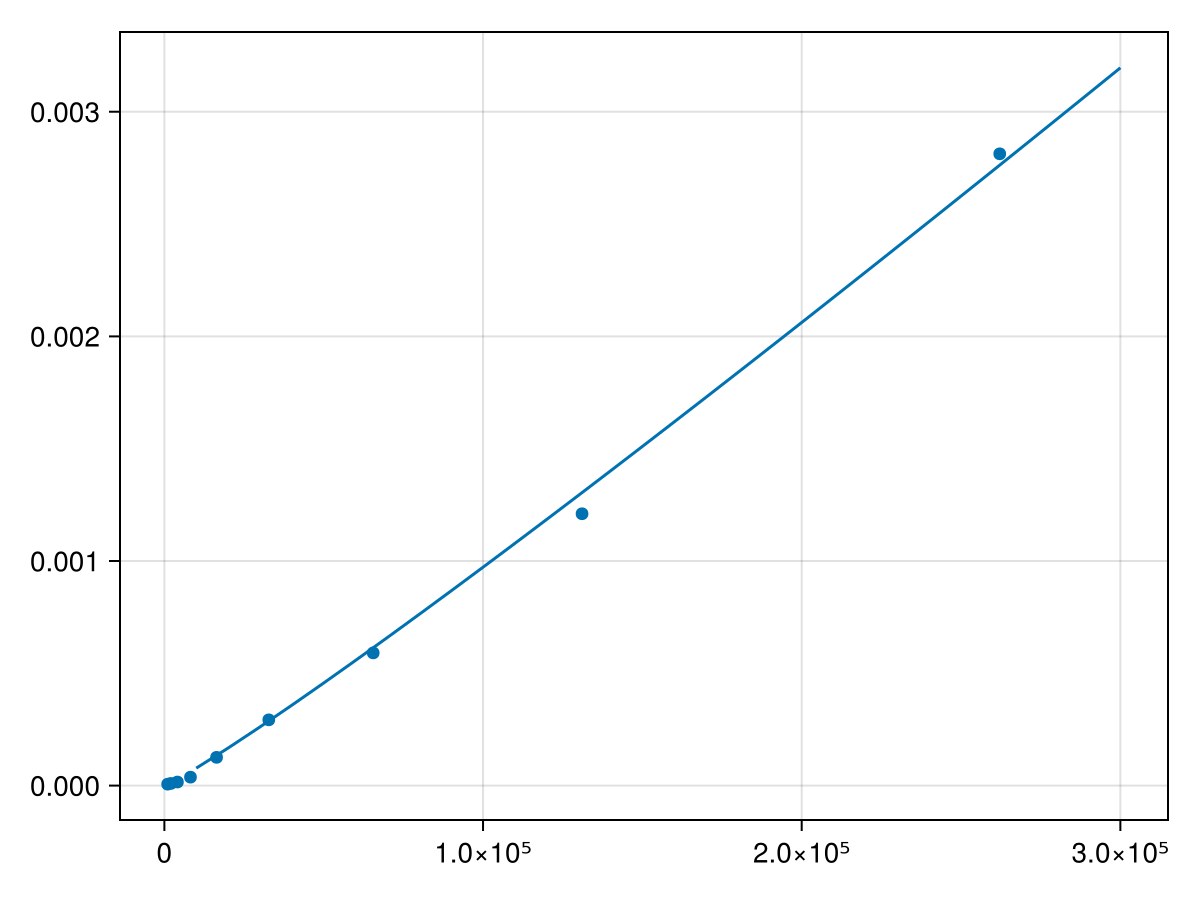
Typically, the best way to analyze an algorithm is to determine the number of operations as a function of \(n\text{,}\) however, let’s look at this as a data analysis problem. As an example, we’ll look at this as the Fast Fourier Transform, discussed in Chapter \ref{ch:complex}. This is a classic example of improving an algorithm to change the order. For this we need the FFTW package, which you probably need to add and
Although both are exclusively positive, the second interval is nearly zero--values near \(10^{-15}\) are often actually 0 and just due to roundoff error. Therefore, we will only use the first term in the model or \(t*log(t)\text{.}\) Trying a new function fit with
This shows using some data analysis that the FFT is \(O(n \ln n)\text{,}\) which can also be shown use analysis of the algorithm, but requires knowledge of how the algorithm works.