In Section 19.5, we saw a method to find the digits of \(\pi\) using random numbers. You should have noticed that it was not a very good method in that it took a million or so random numbers to produce 3 digits of \(\pi\text{.}\) In this chapter, we will explore ways to do it using Power Series, a way of representing functions using calculus.
which is the sum of terms with nonnegative integer powers of \(x\) and an important aspect is that power series do not have a highest power. Nearly every function can be represented by a power series. The classic one is
We will see that the arctangent function and resulting power series can produce the digits of \(\pi\) to many digits. Let’s dive into the power series of arctangent.
function calcPi(n::Integer)
n > 0 || throw(ArgumentError("The input n must be positive."))
local sum = 1.0
for k=1:n
sum += (-1)^k/(2k+1)
end
4*sum
end
for example, we can now determine 10,000 terms of this series with
and this shows that every power of 10 more terms in the series results in about a 1 digit improvement in calculating \(\pi\)--this is because the slope of the line is about \(1\text{.}\) Also since
function atan_series(x::Real,n::Integer)
n > 0 || throw(ArgumentError("The input n must be positive."))
local sum = x
for k=1:n
sum += (-1)^k*x^(2k+1)/(2k+1)
end
sum
end
which uses n terms of the power series of \(\tan^{-1}\) at the value \(x\text{.}\)
which is 1.6860892237957614e-8 so this appears to converge much faster than the method in the previous section. If we repeat with 20 terms, the error is
which is 7.993605777301127e-15, so about 14 digits. You should notice that quite quickly, the value is converging. Since we are quickly running out of precision for 64-bit floats, we will switch to BigFloats and quite easily with:
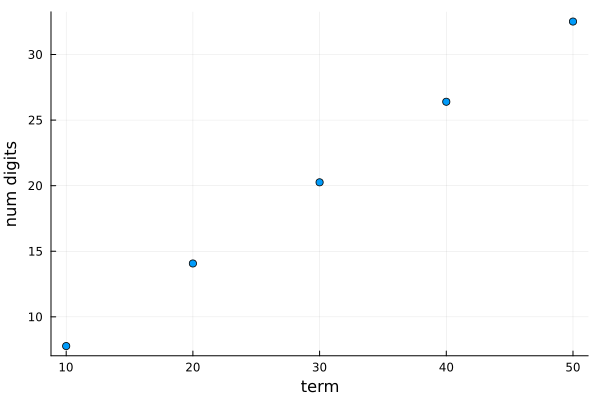
The slope of this line is about \(0.6\text{,}\) which implies that every 10 terms results in another 6 digits of accuracy. Using the plot, we estimate that 100 digits would give an accuracy of over 60 digits and
Since the default number of decimal digits for a BigFloat is about 78 decimal places, we again will quickly run out of precision. Let’s try to see about finding \(\pi\) to 1000 digits. We’re going to adjust the precision of BigFloats, but instead of setting in everywhere we can set it on a block of code with
To estimate the number of terms needed for 1000 digits, a line fitting the data above is about \(d=-0.625(n-20)-14\text{.}\) So a little algebra for letting \(d=-1000\text{,}\) results in \(20-984/-0.625= 1594\) terms. Entering:
The exponential terms is 10 to the \(-964\text{,}\) that is about 964 digits of accuracy. Obviously this didn’t find \(\pi\) to the required 1000 digits. Our estimate was off a bit. Before we adjust this, note that we are really just interested in the number of digits, we can find by taking the log of the result or more-specifically:
Much of this chapter is about speed. We want to be able to calculate \(\pi\) in a reasonable amount of time. We can actually speed up the algorithm in a way similar to the Horner’s form as in Subsection 28.2.1 in the following way. If we write (48.2) in the following way:
function atan_series2(x::Real,n::Integer)
n > 0 || throw(ArgumentError("The input n must be positive."))
local negxsq = -x^2
local sum = 1.0
local ak = 1.0
for k=2:n
ak *= negxsq
sum += ak/(2k-1)
end
x*sum
end
Some of the ways this speeds up is by first calculating \(-x^2\) and this is the only power of \(x\) calculated. Then sums of this term are made. To test the speed, let’s first use the BenchmarkTools package and repeat the example above:
using \(2^{14}\) or 16384 bits results in a BigFloat with 4936 decimal digits. If you play with the power on the precision, note that we need a minimum of \(2^{22}\) binary digits, this should be enough. However, note that at this level of precision, calculations slow down quite a bit. For example,
shows that the same 63 digits of accuracy took 13.153726 seconds. Also, it can be checked that doubling the number of terms will double the number of digits as well as doubling the time. It’s estimated it would take 58 hours to use this method to find \(\pi\) to 1 million digits.
The reason that Euler’s formula worked much better that the first method is that it calculated the arctangents of \(1/2\) and \(1/3\text{.}\) This converges relatively quickly in that power series are powers of \(1/2\) and \(1/3\text{.}\) If we can develop similar formula for fractions closer to zero, this may converge even faster.
and was able to extend what Euler did as well in a much more efficient manner as we will see below. There are a lot of known Machin-type formula that exist (and check out Wikipedia site for some examples). In the 1970s and 1980s with the accelerated power of computers, many mathematicians and computer scientists founds many other formulas like (48.4). For example, in 1982, Kikuo Takano showed that
Subsection48.5.1Using Machin’s Formulas to Calculate \(\pi\)
Notice that in (48.3), (48.4), (48.5) and (48.6), they are all linear combinations of integer coefficients with arctangents of 1 over an integer. Because of this, we can write the following Julia function to calculate all of these:
function machin(coeffs::Vector{Int}, xvals::Vector{T},n::Int) where T <: Integer
length(coeffs) == length(xvals) || throw(ArgumentError("The lengths of the vectors must match"))
local sum=big(0)
for i=1:length(coeffs)
sum += coeffs[i]*atan_series2(1/big(xvals[i]),n)
end
4*sum
end
Then for a testing example, we can reproduce the Euler formula with
results in 141 digits of accuracy in 11.025900 seconds. If we double the number of terms used from 100 to 200, the time roughly doubles to 19.208941 seconds. and the number of terms goes to 352. This would seem to show that to get to million digits would take just about 19 hours, which is shorter than Euler’s method, but not great.
this shows that we get 352 digits of accuracy in 16.688353 seconds. Again, doubling the number of terms doubles both the accuracy (704 digits) and the time it takes (27.553502 seconds). Again, extrapolating, Takano’s method would take 10.87 hours to do 1 million digits.
@time setprecision(2^22) do
numDigits(machin([83,17,-22,-24,-44,12,22],
[big(107),big(1710),big(103697),big(2513489),big(18280007883),big(7939642926390344818), big(3054211727257704725384731479018)], 100))
end
which resulted in 407 digits of accuracy in 25.319640 seconds. Again, doubling the number of terms used doubled the accuracy to 813 digits and took 43.706857 seconds. Extrapolating this would result in a million digits in 14.93 hours. Notice that each of these Machin’s formulas are good, but would take quite a bit of computing time. Notice that the method of Parker was slower than Takano’s formula, but the goal of Matt Parker was to calculate this by hand using the formula. 3
For a bit of a spoiler, the group calculated \(\pi\) to 120 digits during a week of work.
There is a fascinating article in the March 2, 1992 issue of the New Yorker magazine (provide ref) A pair of brothers with last name Chudnovsky built a supercomputer out of mail-order parts in their New York City apartment with the goal of finding the digits of \(\pi\text{.}\) They used the following series:
I won’t get into the details of the story here or Ramanujan, but the New Yorker story is a easy and great read and learning about Ramanujan is yet another wonderful tangent.
function chud(n::Integer)
sum = big(0)
for k=0:n
ak = (-1)^k*factorial(big(6k))/factorial(big(3k))/ factorial(big(k))^3/ (big(640320)^3)^(k+0.5)
sum += big(545140134)*k*ak + big(13591409)*ak
end
1/(12sum)
end
and let’s check out it’s performance by a comparison to Takano’s method above:
and the result shows that this calculates \(\pi\) to 297 digits and took 145 seconds. Note that we only used 20 terms for this calculation. Before, trying to determine the total time to get to 1 million digits, we can use some of the same techniques that we used to speed up the arctangent series in the function atan_series2 as
function chudnovsky(n::Integer)
local sum1 = big(1.0)
local sum2 = big(0.0)
local top = big(1)
local bottom = big(1)
local C = big(640320)^3
for k=1:n
top *= -24*(6*k-5)*(2*k-1)*(6*k-1)
bottom *= C*k^3
sum1 += top/bottom
sum2 += k * top/bottom
end
426880*sqrt(big(10005))/(13591409*sum1 + 545140134*sum2)
end
and the result is 581 digits in 10.962281 seconds and if we go to 80 terms, then we get 1148 terms in 15.179335 seconds. The relationship seems to be roughly linear, so we expect the total time to calculate \(\pi\) to a million digits would be about 3.67 hours.
Subsection48.6.1A parallel version of the Chudnovsky Algorithm
All of the algorithms here in this chapter can be adapted for parallelization because the sums can be split into pieces to be distributed over multiple processors or cores. If you need to, you may want to review the material in Chapter 29 for background on distributed computing in julia.
We rewrite the chudnovsky function so it can be parallelized. We want to be able to break up the sum in (48.8) to sum between \(n_1\) and \(n_2\text{.}\)
@everywhere function paraChud(n1::Integer,n2::Integer,prec::Integer)
setprecision(prec)
local C = big(640320)^3
local bottom = big(1)
local top = big(1)
for k=1:n1
bottom *= k^3*C
top *= -8*(6k-1)*(6k-3)*(6k-5)
end
local sum1 = n1*top/bottom
local sum2 = top/bottom
for k=n1+1:n2
bottom *= k^3*C
top *= -8*(6k-1)*(6k-3)*(6k-5)
sum1 += k*top/bottom
sum2 += top/bottom
end
545140134*sum1 + 13591409*sum2
end
Line 3--11, build up the values of bottom and top needed for the 2nd for loop. These are needed because instead of actually calculating the factorial, we build up the values term by term. Note, we also keep the terms bottom and top as BigInts for speed instead of calculating each term as a BigFloat.
The number that is returned is the number in (48.8) in the parentheses for the terms \(n_1\) through \(n_2\text{.}\) This doesn’t return \(\pi\) because we need to add the terms up first.
which returns nearly the same number of digits (597) in 8.644556 seconds just a bit smaller than the non parallel version. The machine that I am using has 8 cores, so we’ll change the end of the second line to 1:8 or
resulted in 11345 digits of accuracy in 48.279909 seconds and using this method would be predicted that we could calculate \(\pi\) to just over 1 million digits in about 71 minutes. This was on my 8-core Macbook Air. Just for comparison, the New Yorker article cited above mentioned that the Chudnovsky brothers computed \(\pi\) to more that 1 billion digits. It didn’t mention how long it took.
You can’t just take the 18 minutes and multiply by 1000 to get to a billion digits because I used the floating-point precision that was just over a million and would have to scale that.