Optimization is an extremely useful subject in Scientific Computation and is often used in other fields. In short, optimization is the selection of some parameters in order to minimization or maximize some function. A simple example is if we have a function like \(f(x) = x^2\) which has the plot:
a local minimum is a number \(f(c)\text{,}\) such that \(f(x)\geq f(c)\) for all \(x\) in the interval \([c-\epsilon,c+\epsilon]\) for some small \(\epsilon > 0\text{.}\)
a local maximum is a number \(f(c)\text{,}\) such that \(f(x)\geq f(c)\) for all \(x\) in the interval \([c-\epsilon,c+\epsilon]\) for some small \(\epsilon > 0\text{.}\)
We can extend this to functions of more that one variable. The following is the definition of optimal points of functions of two variables and further can be found in [REF??]
Consider a function \(f(x,y)\) that is continuous on some open ball of radius \(\epsilon > 0\) containing the point \((x_0,y_0)\text{,}\) denoted \(B_{(x_0,y_0)}(\epsilon)\)
We saw Newton’s Method in Chapter 10 which found values where \(f(x)=0\text{.}\) If a function is differentiable, then we can use Newton’s Method on \(f'(x)\) to find minima and maxima.
This method works reasonably well to find local minima or maxima of functions of 1 variable if the function is differentiable. However, often, functions are of more than one variable and not differentiable and we would still like to find optimum points. There are other more robust methods that we start with below.
Find all local minima of the function \(f(x) = x^2/2 + \sin(3x)\) on the interval \([-4,4]\text{.}\) Use newton’s method from the Rootfinding module to find the roots.
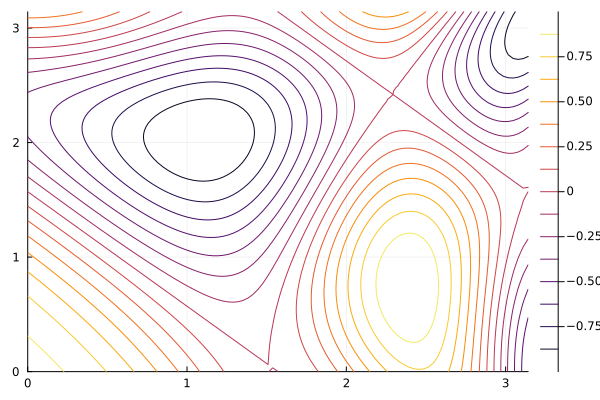
The colors of the contours have heights given on the bar to the side. There is a local minimum near the point \((1,2)\) and we will use a gradient descent method to find this.
The idea with gradient descent is that a starting point is chosen in a manner similar to that of Newton’s method. The gradient of a function, \(\nabla f\text{,}\) denotes a vector showing the direction of greatest increase. Since we are seeking a minimum, the direction of greatest descent is the opposite direction or \(-\nabla f\text{.}\)
function gradientDescent(f::Function,x₀::Vector; γ = 0.25, max_steps = 100)
local steps = 0
local ∇f₀ = [1,1] # initialize it to get into while loop
while norm(∇f₀) > 1e-8 && steps < max_steps
∇f₀ = ForwardDiff.gradient(f,x₀)
x₀ = x₀ - γ*∇f₀
steps += 1
end
steps < max_steps || throw(ErrorException("The number of steps has exceeded $max_steps"))
x₀
end
and we can use this code 1
To get the \(\nabla\) symbol above, type \nabla, then hit TAB. To get subscripts like x₀, type xthen \_0then hit tab. You can get other numerical subscripts with other digits after the underscore.
to find a minimum of the function in (44.1), first we define it as
where the value x needs to be a Vector, which is a 1D array, for the ease of taking gradients with the ForwardDiff.gradientfunction. The standard \(x\) and \(y\) variables are x[1]and x[2]respectively. To find the minimum with this function use:
The maximum can be found using this same method by finding the minimum of the negative of this function. Find the maximum of this same function near the point \((2.5,0.5)\text{.}\)
We used a constant for the value \(\gamma\) above, however, in [REF!!!], Barzilai and Borwein developed a steepest descent method that acts much like Newton’s method in term of convergence speed by selecting:
Note, though that \(\gamma_n\) requires knowing information at the previous step (both \(\mathbf{x}_{n-1}\) and \(\nabla f(\mathbf{x}_{n-1})\)) which is not available on the first step. We can use the simple gradient descent (where we used a constant value of \(\gamma\)) on the first step and then
Section44.3Fitting Data to a Line -- Linear Regression
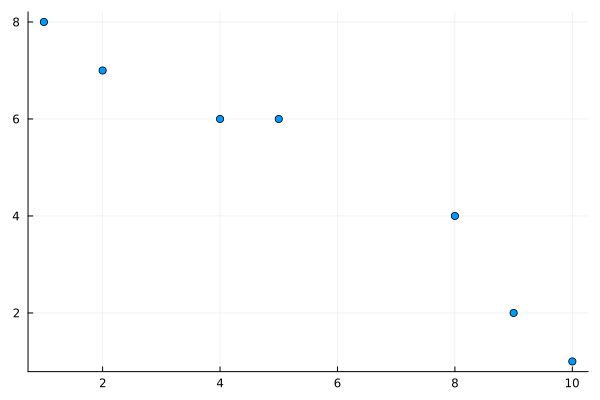
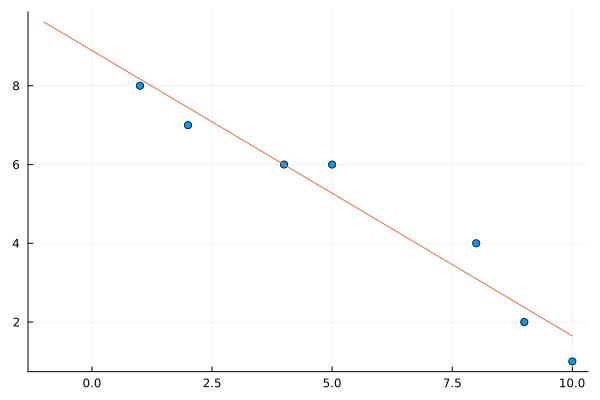
We saw in Chapter 28 of fitting various functions to data. We skipped over a lot of details there by using a package called LsqFit. We’re going to revisit this by using the techniques here, which allows use to find fits in more generally ways than using that package. We’ll start with a common task of finding the best fit line through a set of points and let’s just take a small example. Let
and we want to minimize this recalling that the variables are \(m\) and \(b\) (note that \(x\) and \(y\) are the data). Basically, this comes down to defining the function \(E\) in julia and using one of the methods from above. We can write \(E\) down like
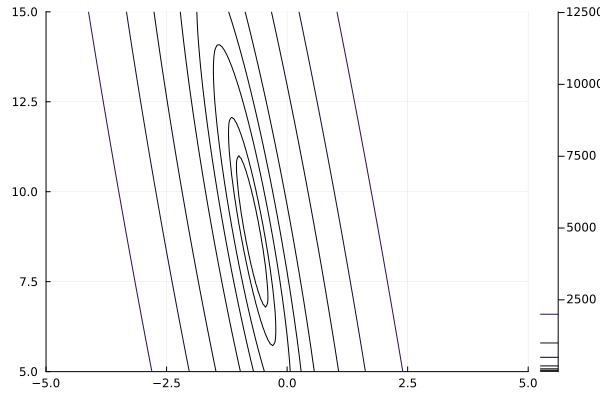
the result is The number of steps has exceeded 100. Oops. This is common for some functions of more that one variable. If we look at a contour plot with the command:
you can see that there appears to be a minimum, however it is in a long narrow canyon. This is a common example where gradient descent does not work well, even if we try different values of \(\gamma\text{.}\) (Try it!!) Instead, if we use the Barzilai–Borwein method,
As discussed elsewhere, a polynomial has many nice properties for a function. This includes 1) there are only multiplications, additions and subtractions of numerical values to evaluate it (these are all fast operations on a CPU) and 2) horner’s form of the polynomial make them super fast to evaluate. Because of this, using a polynomial as way to calculate other functions is common.
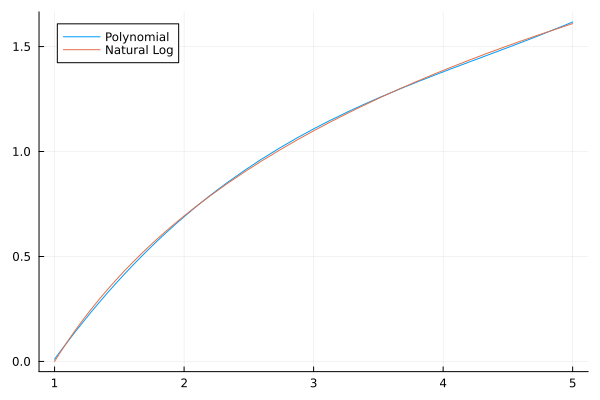
In this section, we will fit a polynomial to a natural logarithm. It will be similar to fitting data to a line, except the data will be generated from a function and we will use a polynomial (of some degree as the fit). Let’s try to fit a cubic to a set of data generated by \(y=\ln (x)\) on \([1,5]\text{.}\) We first generate the x points with
and this shows that with just a cubic, we can approximate the natural log to 0.016 (almost 2 digits). If we choose a higher-degree polynomial, we can do better and in fact, using polynomials as approximations is often the way that many mathematical functions are evaluated.
There is a very nice package for optimization called the JuMP package \cite{DunningHuchetteLubin2017} which allows the ability to set up a problem, then optimize it. Make sure you add the following packages and then
and note that there was no output. This only adds the two variables as well as the objective function and since it is nonlinear, we use the @NLobjectivemacro.
******************************************************************************
This program contains Ipopt, a library for large-scale nonlinear optimization.
Ipopt is released as open source code under the Eclipse Public License (EPL).
For more information visit https://github.com/coin-or/Ipopt
******************************************************************************
This is Ipopt version 3.14.14, running with linear solver MUMPS 5.6.2.
Number of nonzeros in equality constraint Jacobian...: 0
Number of nonzeros in inequality constraint Jacobian.: 0
Number of nonzeros in Lagrangian Hessian.............: 3
Total number of variables............................: 2
variables with only lower bounds: 0
variables with lower and upper bounds: 0
variables with only upper bounds: 0
Total number of equality constraints.................: 0
Total number of inequality constraints...............: 0
inequality constraints with only lower bounds: 0
inequality constraints with lower and upper bounds: 0
inequality constraints with only upper bounds: 0
iter objective inf_pr inf_du lg(mu) ||d|| lg(rg) alpha_du alpha_pr ls
0 8.9014960e-01 0.00e+00 2.21e-01 -1.0 0.00e+00 - 0.00e+00 0.00e+00 0
1 8.8938129e-01 0.00e+00 2.26e-01 -1.7 2.26e-03 2.0 1.00e+00 1.00e+00f 1
2 8.8683604e-01 0.00e+00 2.40e-01 -1.7 7.19e-03 1.5 1.00e+00 1.00e+00f 1
3 8.7635157e-01 0.00e+00 2.89e-01 -1.7 2.61e-02 1.0 1.00e+00 1.00e+00f 1
4 7.7132679e-01 0.00e+00 5.70e-01 -1.7 1.59e-01 0.6 1.00e+00 1.00e+00f 1
5 7.0600048e-01 0.00e+00 6.73e-01 -1.7 6.88e-02 1.0 1.00e+00 1.00e+00f 1
6 2.3792272e-01 0.00e+00 9.03e-01 -1.7 3.57e-01 0.5 1.00e+00 1.00e+00f 1
7 -8.1257894e-01 0.00e+00 6.74e-01 -1.7 1.13e+00 0.0 1.00e+00 1.00e+00f 1
8 -9.5265426e-01 0.00e+00 4.47e-01 -1.7 5.61e-01 - 1.00e+00 1.00e+00f 1
9 -9.9993858e-01 0.00e+00 1.64e-02 -1.7 2.12e-01 - 1.00e+00 1.00e+00f 1
iter objective inf_pr inf_du lg(mu) ||d|| lg(rg) alpha_du alpha_pr ls
10 -1.0000000e+00 0.00e+00 9.57e-05 -3.8 7.48e-03 - 1.00e+00 1.00e+00f 1
11 -1.0000000e+00 0.00e+00 3.43e-09 -5.7 4.25e-05 - 1.00e+00 1.00e+00f 1
Number of Iterations....: 11
(scaled) (unscaled)
Objective...............: -1.0000000000000000e+00 -1.0000000000000000e+00
Dual infeasibility......: 3.4309616552489507e-09 3.4309616552489507e-09
Constraint violation....: 0.0000000000000000e+00 0.0000000000000000e+00
Variable bound violation: 0.0000000000000000e+00 0.0000000000000000e+00
Complementarity.........: 0.0000000000000000e+00 0.0000000000000000e+00
Overall NLP error.......: 3.4309616552489507e-09 3.4309616552489507e-09
Number of objective function evaluations = 12
Number of objective gradient evaluations = 12
Number of equality constraint evaluations = 0
Number of inequality constraint evaluations = 0
Number of equality constraint Jacobian evaluations = 0
Number of inequality constraint Jacobian evaluations = 0
Number of Lagrangian Hessian evaluations = 11
Total seconds in IPOPT = 0.032
EXIT: Optimal Solution Found.
There’s a lot to unpack here, but there just a few things to note:
All of the steps are shown. This took 11 steps and you see the objective column reports the value of the objective starting at the point \((0.1,0.1)\) with value 8.901e-01and decreasing to -1.0e+00
There are total number of function, gradient, Jacobian and Hessian evaluations, where the latter two are matrices of derivatives. Like we did in defining our gradient descent function, these are done with the ForwardDiffpackage. This is helpful if your function takes a long time to compute to see where time is spent.
model = Model(Ipopt.Optimizer)
set_optimizer_attribute(model,"print_level",3)
@variable(model,m,start=0)
@variable(model,b,start=0)
@NLobjective(model,Min, sum((m*pt[1]+b-pt[2])^2 for pt in pts))
optimize!(model)
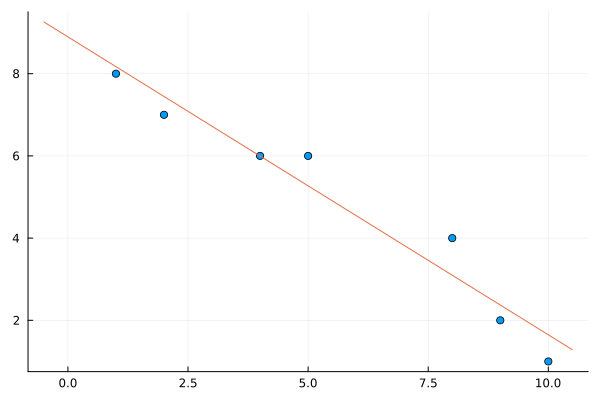
where we have set the print_levelattribute of the Ipopt solver to 3 to print out less information. Also, note that the way the objective function is called And we haven’t shown the information here, but the most important aspect is that it found the solution. The values are